
My name is Zhuofan Xia (“夏卓凡” in Chinese). I’m currently a 4th-year Ph.D. candidate at Department of Automation, Tsinghua University, advised by Prof. Gao Huang and Prof. Shiji Song. Before that, I did my bachelor degree in Automation at Tsinghua University in 2020. My research mainly focuses on deep learning on computer vision, and multimodal learning. Specifically, my research interests lie in the Vision Transformers (2D / 3D), dynamic neural architectures, and large multimodal models. Currently, I am focusing on the topics related to dynamic and efficient large multimodal models.
Download my C.V. (possibly outdated) here.
📖 Education
- 2020.08 - 2026.06 (Expected), 🧑🎓 Ph.D. in Control Science and Engineering, Tsinghua University, Beijing, China.
- Advised by Prof. Gao Huang and Prof. Shiji Song.
- 2016.08 - 2020.06, 🧑🎓 B.Eng. in Automation, Tsinghua University, Beijing, China.
📝 Selected Publications 
*: equal contribution, †: corresponding author.
For full publication list, please check my Google Scholar profile.

Agent Attention: On the Integration of Softmax and Linear Attention
European Conference on Computer Vision (ECCV), 2024
Dongchen Han*, Tianzhu Ye*, Yizeng Han, Zhuofan Xia, Shiji Song, Gao Huang†

GSVA: Generalized Segmentation via Multimodal Large Language Models
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Zhuofan Xia*, Dongchen Han*, Yizeng Han, Xuran Pan, Shiji Song, Gao Huang†

DAT++: Spatially Dynamic Vision Transformer with Deformable Attention
Preprint
Zhuofan Xia, Xuran Pan, Shiji Song, Li Erran Li, Gao Huang†

Adaptive Rotated Convolution for Rotated Object Detection
IEEE/CVF International Conference on Computer Vision (ICCV), 2023
Yifan Pu*, Yiru Wang*, Zhuofan Xia, Yizeng Han, Yulin Wang, Weihao Gan, Zidong Wang, Shiji Song, Gao Huang†

Slide-Transformer: Hierarchical Vision Transformer with Local Self-Attention
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
Xuran Pan* Tianzhu Ye*, Zhuofan Xia, Shiji Song, Gao Huang†

Budgeted Training for Vision Transformer
International Conference on Learning Representations (ICLR), 2023
Zhuofan Xia*, Xuran Pan*, Xuan Jin*, Yuan He, Hui Xue, Shiji Song, Gao Huang†

Vision Transformer with Deformable Attention
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Best Paper Finalists (0.4%)
Zhuofan Xia*, Xuran Pan*, Shiji Song, Li Erran Li, Gao Huang†

3D Object Detection with Pointformer
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Xuran Pan*, Zhuofan Xia*, Shiji Song, Li Erran Li, Gao Huang†
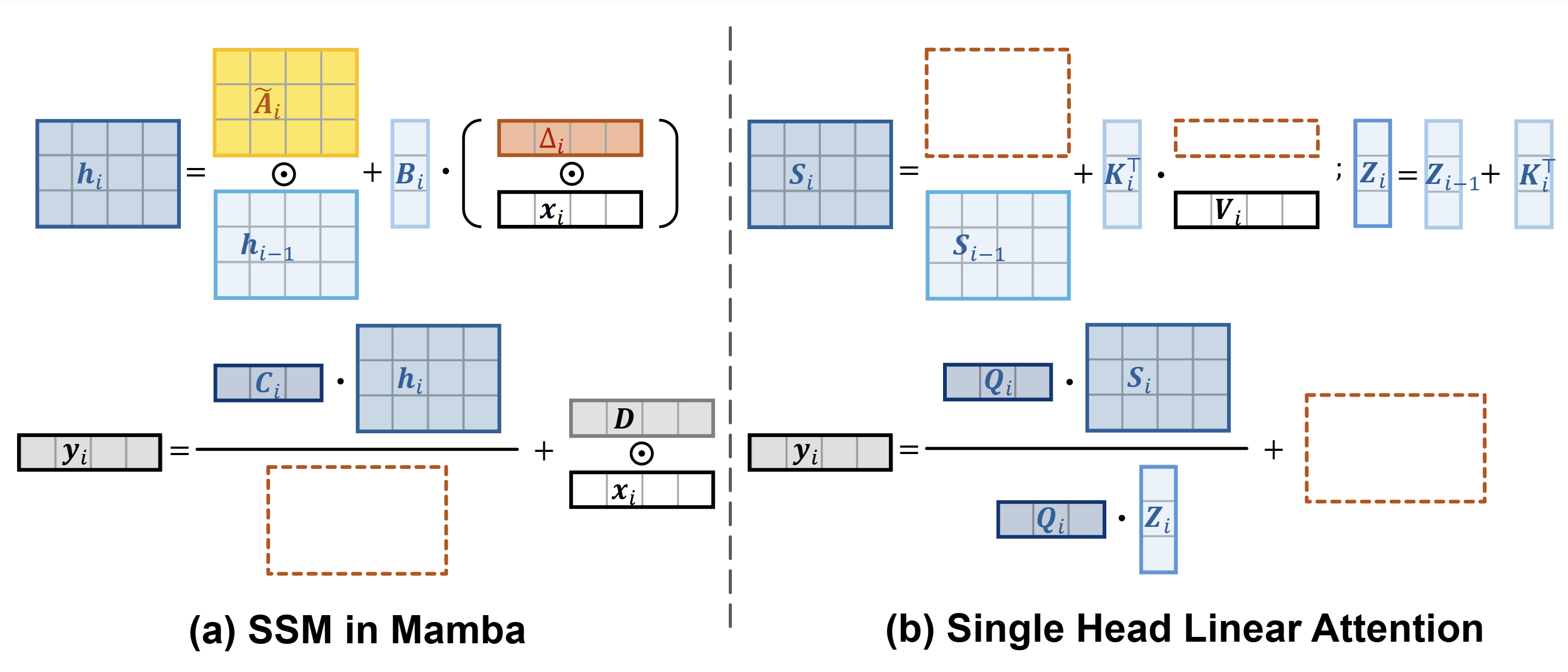
Demystify Mamba in Vision: A Linear Attention Perspective
Preprint
Dongchen Han, Ziyi Wang, Zhuofan Xia, Yizeng Han, Yifan Pu, Chunjiang Ge, Jun Song, Shiji Song, Bo Zheng, Gao Huang†
🎖 Honors and Awards
During PhD
- Fall 2023, Friend of Tsinghua – Ubiquant Scholarship of Tsinghua University, on Comprehensive excellence.
- Fall 2022, Friend of Tsinghua – Hefei Talent Scholarship of Tsinghua University, on Comprehensive excellence.
- Fall 2021, Friend of Tsinghua – Samsung Scholarship of Tsinghua University, on Comprehensive excellence.
During Undergraduate
- Fall 2019, Friend of Tsinghua – Evergrand Scholarship of Tsinghua University on Academic excellence.
- Fall 2019, Outstanding Social Work Scholarship of Tsinghua University on Outstanding social work.
- Fall 2018, Friend of Tsinghua – Zhang Ronghua Scholarship of Tsinghua University on Academic excellence.
- Fall 2018, Outstanding Social Work Scholarship of Tsinghua University on Outstanding social work.
- Fall 2017, Academic Excellence Scholarship of Tsinghua University on Academic excellence.
🎓 Academic Services
- Reviewer for ICCV(2023), CVPR(2024), ECCV(2024), NeurIPS(2024), ICLR(2025).
- Reviewer for IJCV, IEEE TCSVT.
💬 Invited Talks
-
2024.04, Online, AI Time [video] talk on GSVA: Generalized Segmentation via Multimodal Large Language Models.
-
2022.08, Tianjin, VALSE 2022 Student Workshop, talk on Vision Transformer with Deformable Attention.
-
2022.07, Online, AI Time [video], talk on Vision Transformer with Deformable Attention.